Colors


Dom Pedro V who was one of the kings of Portugal is also the eponym of the street in Porto we live in.

We found him also in the Monte Palace Tropical Garden. Not to be confused with the botanical garden.
The display is on the typical Portuguese tiles called Azulejo.
We were on vacation. When returning we had this view from the balcony. Hint: Not many runways are trapped between the airport building and the mountains.

Check here if your guess was correct.
The snack vending machine in office got an update for cashless payment. And it looks like it also needs a software update.

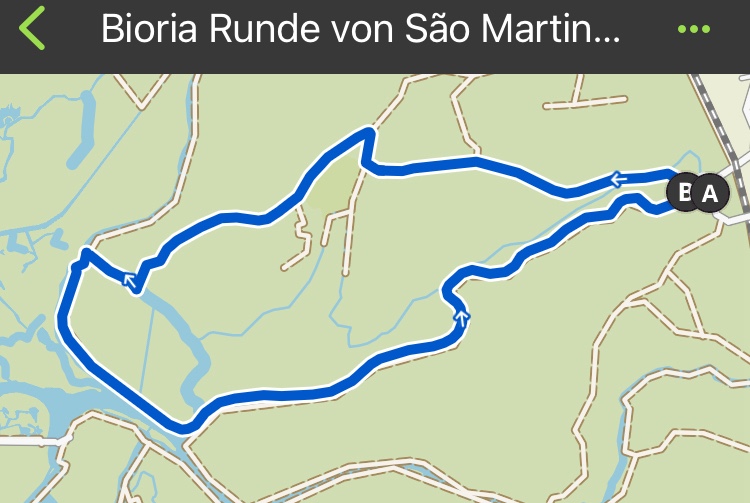
We went to the Serra de Midões e de Pias just 20 minutes from home.

and did a relatively short tour mostly along the Rio de Ferreira.
On the komoot map it looked initially like we could cross the river and take shortcut. But it turned out that this is only possible in summer. The river crossings were not possible with the amount of water in the river. So towards the end we had to climb a rather steep path. For the spoiled German member of the Schwarzwaldverein – used to having clear markings and walkable paths everywhere – it was a learning. Nevertheless a nice tour and on the way we found some nice places to rest and with a good view.
We went to the movie theater and in the middle of the movie – which was after 45 minutes – this

appeared. Last time I have experienced an intermission was between two movies of LOTR.
This time it was a kids movie: Patos! Based on the booking information it was supposed to be the OV but it turned out to be the Portuguese version. Since the ducks did not discuss philosophy we were able to follow anyway and had fun.
While I did not further investigate the real reason for the intermission I believe it is intended as service break for the young audience.
We tastet the local specialty of Aveiro. Ovos moles. Very sweet.

Aveiro is the “Venice of Portugal” because of it’s canals, bridges and boats.

Instead of locks with names the bridges are decorated with ribbons of friendship.
After 4 weeks of rain we enjoyed the nice weather.
Climate is changing. That’s not really new. However it was new to me that Portugal has a skiing region. It’s located in the Serra da Estrela. But due to less snow and warmer winters skiing is in decline and lifts are closing.

There is also an active lift which in summer is used by hikers.

And there is political change. The radar towers are remnants of the Cold War. Portuguese Air Force and NATO do not need them any more.

Another invasive species crossed our way. The common water hyacinth.

Probably the most famous sweet of Portugal: Pastel de Nata.

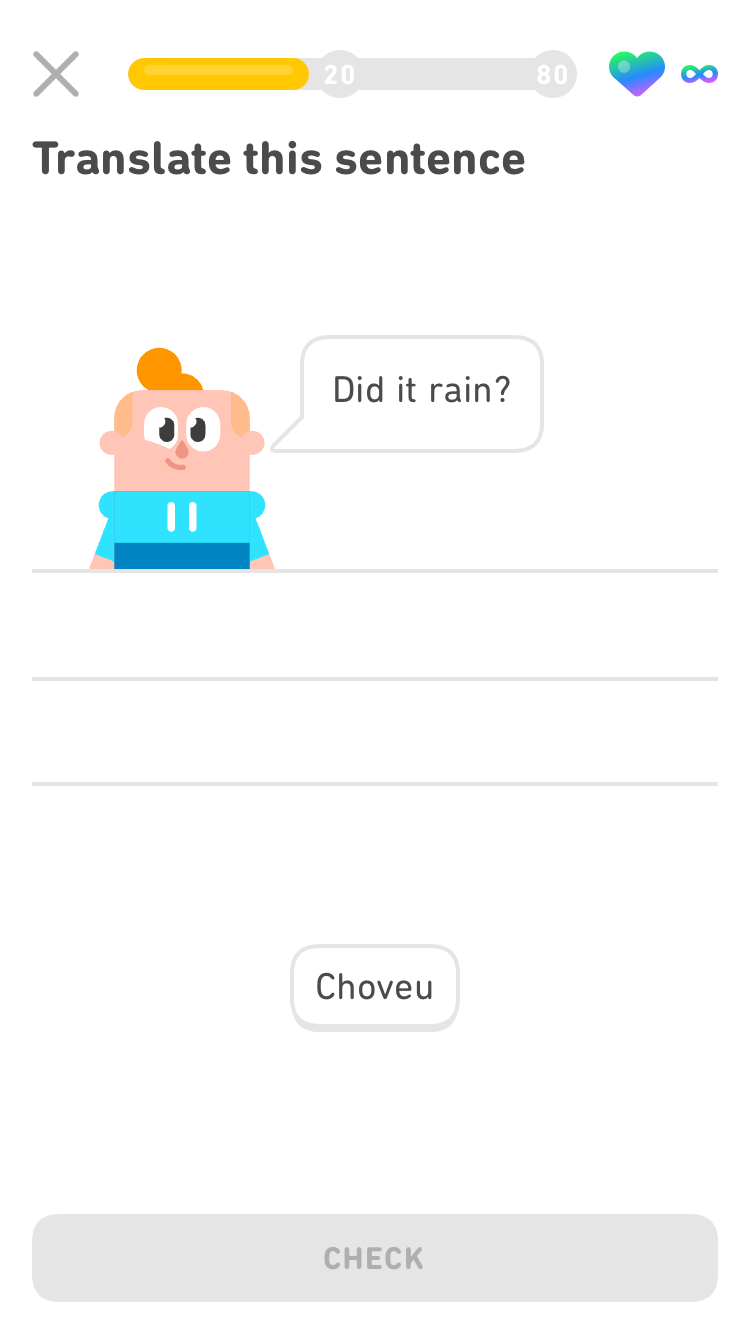
I’ll need many more attempts.
While I like Duolingo in general the latest updates could have been better.
While taking a walk between Espinho and Esmoriz this little guy got a little bit defensive.

While it’s looking nice it’s another invasive species. It even made it to Berlin.
Most wildfires in Portugal happen in the south. But the risk is there everywhere. In the Serra de Estrela it happened xxx years ago. Now nature is slowly recovering.

I was wondering why in some places the trees have survived while a few meters to the right and left are completely burnt.
Unlike the one in the other post this

bridge is an actual Eiffel bridge. It’s located in Viana do Castelo, which we’ve visited to finalize the immigration process for Portugal at the SEF.
It’s noteworthy that above the visible rail track there is also a second level for cars. We took a little bit of a detour to use this bridge on our way back.
We came to know that, cortaderia selloana, the nice looking grass/reed that can be found everywhere is actually an invasive species.
Because of it’s invasive nature it appears on the website of the Parque Biologico de Gaia that we’ve visited. It’s a nice park with local animals.

All of them needed some kind of support, because they were found injured or abandoned by the parents so I think it’s good they found a new home. My favorite was the costal biorama.
… but the programmers of the Withings app wanted to make sure that I’m aware that there is nothing to see.
Spending one third of the screen to tell that there’s nothing new seems to be wrong.

The German school in Porto has it’s own Oktoberfest. It was fun and games for the kids and of course you meet more BOSCHlers.
I received a care package. Ingredients for the world famous “Linsen, Spätzle und Saitenwürstle”.

Plus canned sausage. All a Swabian needs. Except bread. Like all, or at least most, other Germans living abroad: Bread is a topic that requires some intensive investigation.
Next to our house is a heli pad. Never saw it in action before. Today I caught it.

However I’ve not yet seen it on any flight tracking site. I might have to start up the old TV usb stick.